Profiles of Innovation: A New Way to Look at Data

This article was co-authored by Andrew Mori and Vahe Koestline.
We do a lot with data at VideoAmp. Our data is not just for use by data scientists, but also data engineers, developers and product owners. Providing access to our data for all who needed it was difficult since we had many disparate data sets with different methods of querying the data. Prior to using Dremio, we had to setup a Jupyter notebook which was capable of joining these datasets in Spark across our HDFS, Postgres, CSV, and other data sets.
This required a fair amount of programming experience, and was out of reach for our product folks who have SQL experience. Our product team and others were reliant on team members with Spark skills to extract and transform data so that it could be used in a meaningful way. We needed a way to provide a holistic view of our data and allow for greater ability to explore it. This would also break down silos and bottlenecks across our organization.
Enter Dremio.
Dremio caught our attention as it had many connectors that provide users with metadata across Hive, RDS, and ElasticSearch as well as provide views into file systems such as HDFS, S3, and NAS. It also provided a simple UI that would allow and manage tables, data definitions, queries, and other aspects of what our team members would do with the data.
Setup
After deciding to explore Dremio, the next steps were to setup a proof-of-concept using the open source version of Dremio. Luckily, installation was as easy as running yum install of a rpm provided by Dremio. The initial setup was running Dremio in standalone mode, with the coordinator and worker running on the same box. Configuration required providing a few Hadoop configuration files such as hive-site.xml and core-site.xml.
After running “start dremio service” we were able to view the UI and connect Dremio to Hive, S3, Hdfs, and Postgres RDS instances. Next, we tested running queries outside of exploring the structure of Hive databases. When test-running queries on Hive tables, we ran into authentication issues, looking into the docs it was required to setup impersonation for the user “dremio.” We were able to get queries to work on Hive with one caveat being that the account running Dremio queries on Hive had to be user “dremio.” It would not be until we productionalized of Dremio were we able to solve this, but for the POC, this was fine.
After testing standalone mode, we wanted to test scaling out Dremio workers on Yarn. Setup was also fairly painless, with some issues around passing the correct S3 access / secret keys to allow Dremio to use S3 for storing job results, downloads, uploads, etc.
The biggest issues with setting up the POC for Dremio were holes in the documentation. For example when dealing with the Dremio impersonation issues, the documentation provided only worked partially and not for every user. There was no concrete information within the Hive settings that needed to be updated to allow for access. Another issue that would need to be addressed was tuning the coordinator process as default settings were causing frequent timeouts or process crashes. Despite these issues, we were able to fully test the POC to validate and establish buy-in with our key stakeholders.
Now that we had established a viable POC with Dremio, the next step was to productionalize it. This involved a number of tasks including addressing stability, disaster recovery, scalability, tooling, data management and configuration management.
The architecture we decided on is below:
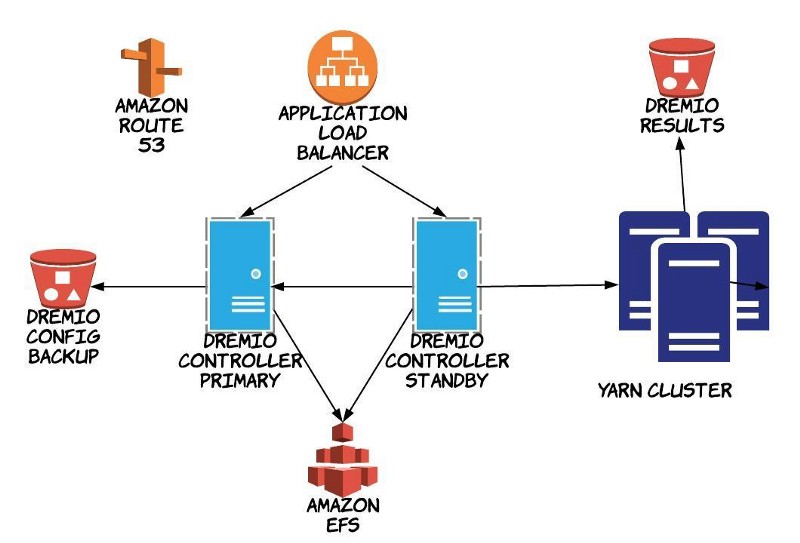
Configuration management and our automated build process involved using AWS Opsworks and Chef recipes to manage the install and configuration of the Dremio tool. There were also additional configurations that needed to be added to Hive to allow for the Dremio tool to be able to impersonate users when querying Hive datasets. This was a difficult challenge as it required some custom configurations that were not documented.
For stability and disaster recovery, we employed an active-standby with our Dremio Controller. The controller configurations, which include dataset and datasource configurations, were stored on AWS EFS so that we could share the mount between the two controllers. We added some additional tooling to allow the standby to automatically fail over. In addition, we also backup configurations to AWS S3 regularly to ensure any corruption of configs can be undone with a simple restore of configurations.
As for the query results, we store the results on S3 and expunge result set after 7 days to ensure we are managing our data and bucket reasonably. We also enabled the collection of metrics through Grafana and monitoring through Sensu to provide us visibility and the ability to quickly recover from any future incidents.
We employed Yarn to manage the scheduling and execution of queries across a cluster of servers. Another challenge was determining the number of worker threads and performance tuning them to allow for maximum performance. Our first iteration crashed regularly and had many long running queries that crashed. This was due to the default JVM settings. These settings were tuned to be able to manage a production load and we observed that previously long running queries were returning with results incredibly fast. The JVM tuning was done as we rolled out a beta of the Dremio tool to our teams. Their uses of the Dremio tool allowed us to monitor and get the performance tuned exactly how we wanted.
In addition to the UI provided by Dremio, we knew that a lot of our engineers like to use Jupyter Notebooks when accessing and querying our data. From a usability perspective, it made sense to give that same flexibility in Jupyter. Dremio provided an ODBC driver which we installed and templatized so that our teams can use them in their running Jupyter instances, providing a second way of accessing the data. With this last piece in place, the productionalizing of Dremio was complete and we were ready to make this available to everyone.
New Capabilities
The biggest impact of Dremio was that we now have a unified place and an easy way to view our data. Our production setup of Dremio pulls in data from RDS, Hive, HDFS, S3, ElasticSearch, and Jupyter. This allows our customer service and product engineers additional access and the ability to query data that was not previously available to them. This also allowed our data teams to query across multiple datasets in a simpler method using the SQL editor in Dremio instead of ETL jobs in Spark. As a result, our product managers are now empowered to answer key business questions without needing to rely on data engineers or operations teams to write or provide Spark ETL jobs. The ability to store results in S3 also enables a simple way to create new datasets that can them be used in future queries.
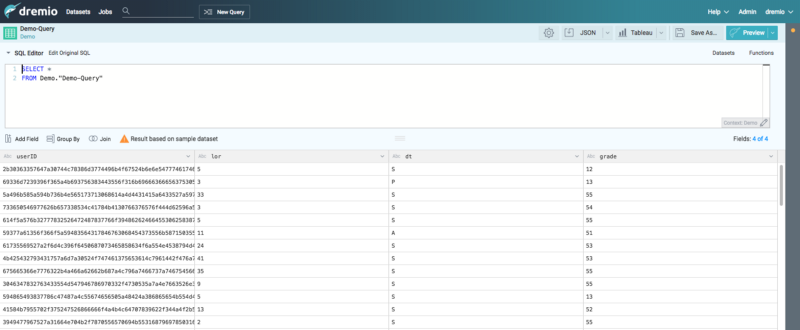
Diagram A: A simple query to inspect one of our tables in Hive
Note: Data has been cleansed and sanitized for this blog
We noticed the adoption rate quickly picked up across different teams and we constantly received feedback of how it has helped our team members in day-to-day operations. Team members are frequently performing complex tasks like joining data across disparate data sources
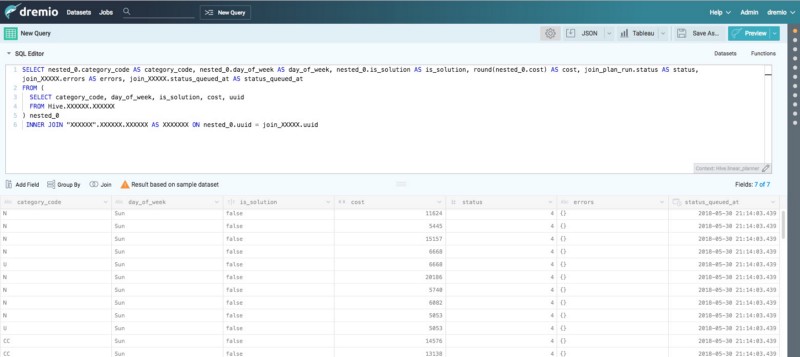
Diagram B: Joining multiple disparate data sources (Hive and RDS) using the query generator UI
Note: Data has been cleansed and sanitized for this blog
Future Improvements
Now that we have Dremio, we’re excited to see the future enhancements that will come with this product. Some easy wins would be to increase available datasets including adding Google Cloud Storage, which some of our clients use. We also have a desire to explore its uses within the operations and devops world with respect to improving observability through efficiently querying against system performance metrics and application logs. We also have a desire to hook this tool into BI, machine learning, and visualization tools that will give us better clarity on our data.
