More Concise Data Transformation Tests

Most software developers acknowledge automated testing as an essential part of their work. Yet, we often see developers who work on data transformations in ETL pipelines omitting automated testing from their process.
Insufficient testing can allow inaccurate data to flow through a system. For public-facing data sets, this is not a good look. Even for internally consumed reports, data errors can lead to inaccurate reporting, suboptimal decisions, and/or a general lack of faith in the data warehouse. We rely heavily on our tests to make sure we are providing clean data to our data science team for data mining and machine learning efforts.
In some cases, developers may feel that they should or would like to include tests, but still haven’t gotten into the habit, in part because writing such tests can be cumbersome.
At VideoAmp, we use Apache Spark to perform many of our transformations on some very large data sets, such as tracking people’s TV viewing behavior. Some of these data transformation examples are very complex, and thorough testing is essential for their transparency and integrity.
Problems With the “Golden Data Set”
One common approach is the “golden data set” (not to be confused with the “golden record”), where a developer has a set of input data that is known to be good, most likely as a result of obtaining some input data, transforming it, then visually inspecting the output data for accuracy. The golden data set is fed as input to the transformation code, then the output is checked for accuracy.
One possible pitfall of the golden data set is that developers sometimes include more data than is needed to achieve the goals of the test. The best defense here is for the developer to be diligent in reducing the amount of data to the bare minimum required to cover the required test cases.
A related pitfall is that the golden data set may contain multiple embedded test cases and edge cases, though it may not be clear exactly how many different test cases are present.
In unit tests for more linear code (a sorting algorithm written in Python, for example), it is both common and recommended to have a discrete and easily identifiable test method for each individual test case. When testing data transformations, this sort of purity, while theoretically useful, can be cumbersome and even impractical for two main reasons.
First, for a test that must populate a database (even a few rows in a local, memory-based temporary database), the setup time can be relatively lengthy. This is particularly true when using Spark and Hive. Sometimes we find ourselves trying to avoid adding too many separate tests in order to keep our test suite runtime to a comfortable duration.
Second, in many cases there are interactions between different rows in the input data set. For example, the transformation under test may need to group certain rows by a compound primary key and take only the resulting row with the most recent creation date.
We’ve seen tests of sophisticated transformations that have had a dozen or more edge cases embedded with them. In these situations, the practical reality is that a developer is unlikely to want to take the time to set up and tear down separate tests for each condition. So, practically speaking, the choice is often between embedding multiple test conditions in a single test or simply foregoing the coverage. Faced with that tradeoff, we prefer having the coverage.
One technique that can help avoid both of these pitfalls is to allow comments in our input data set. This makes it easier to document the significance of each piece of test data for the different test conditions that are contained in the data.
We also find it helpful to have input and output data within the same file. If we notice a piece of information in the input data (a ZIP code, for example), and would like to see where it shows up in the output data, combining the inputs and outputs in a single file makes it simpler to search for both occurrences.
Based on these observations, we had a couple of goals in mind for our tests of Spark data transformations:
- Provide a way to concisely express the input and expected output data within the test file itself.
- Allow comments on the input and output data sets in order to clarify what is being tested.
We have developed a small, lightweight library that makes it quicker for us to write such tests. It also makes these tests more concise and easy to read when we inevitably must adapt the code and its tests to accommodate increasingly complex conditions in the data as it evolves.
DataFrame Show Reader
In order to read and write our tests more easily, we have created and continue to maintain the open source py-dataframe-show-reader library.
In Spark, the output of the DataFrame.show() command is visually easy to read and very compact. For example:

py-dataframe-show-reader is a Python library that reads the output of a Spark DataFrame.show() statement and “rehydrates” it into a PySpark DataFrame that can be used as test input, either by passing the DataFrame directly to the method under test or by persisting it to a local Hive database, depending on what the method under test requires.
Imagine we are working on a Python method that uses PySpark to perform a data transformation that is not terribly complex, but complicated enough that we would like to verify that it performs as intended. For example, consider this function that accepts a PySpark DataFrame containing daily sales figures and returns a DataFrame containing weekly sales summaries:

This is not a complex method, but perhaps we would like to verify that:
- Dates are in fact grouped into different weeks.
- Units sold are actually averaged and not summed.
- Gross sales are truly summed and not averaged.
A unit testing purist might argue that each of these assertions should be covered by a separate test method, but there are at least two reasons why one might choose not to do that.
- Practical experience tells us that detectable overhead is incurred for each separate PySpark transformation test, so we may want to limit the number of separate tests in order to keep our full test suite running in a reasonable duration.
- When working with data sets as we do in Spark or SQL, particularly when using aggregate, grouping and window functions, interactions between different rows can be easy to overlook. Tweaking a query to fix an aggregate function like a summation might inadvertently break the intended behavior of a windowing function in the query. A change to the query might allow a summation-only unit test to pass while leaving broken window function behavior undetected because we have neglected to update the window-function-only unit test.
If we accept that we’d like to use a single test to verify the three requirements of our query, we need three rows in our input DataFrame.
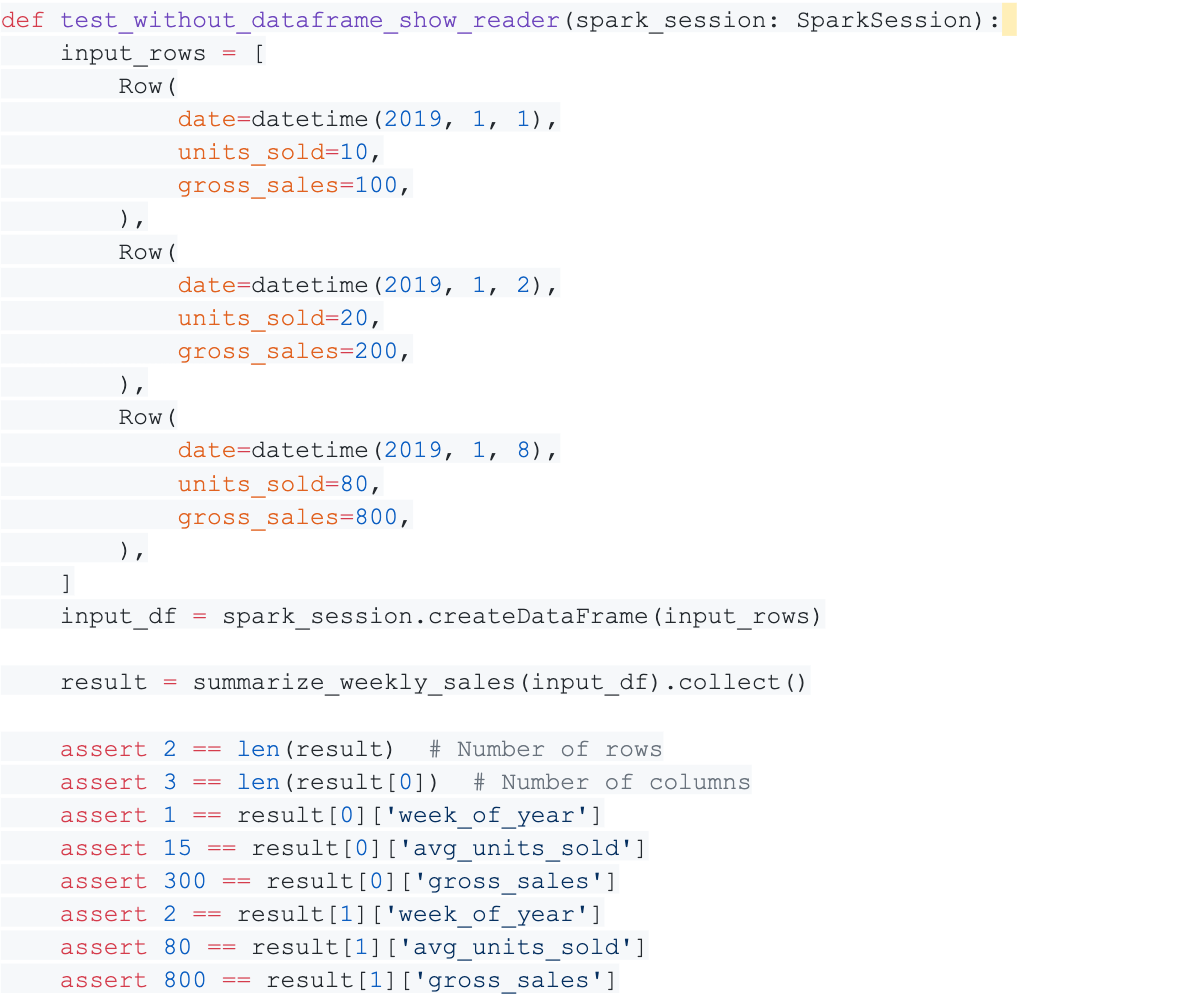
Using unadorned pytest, our test might look like this:
Using the DataFrame Show Reader, our test could instead look like this:
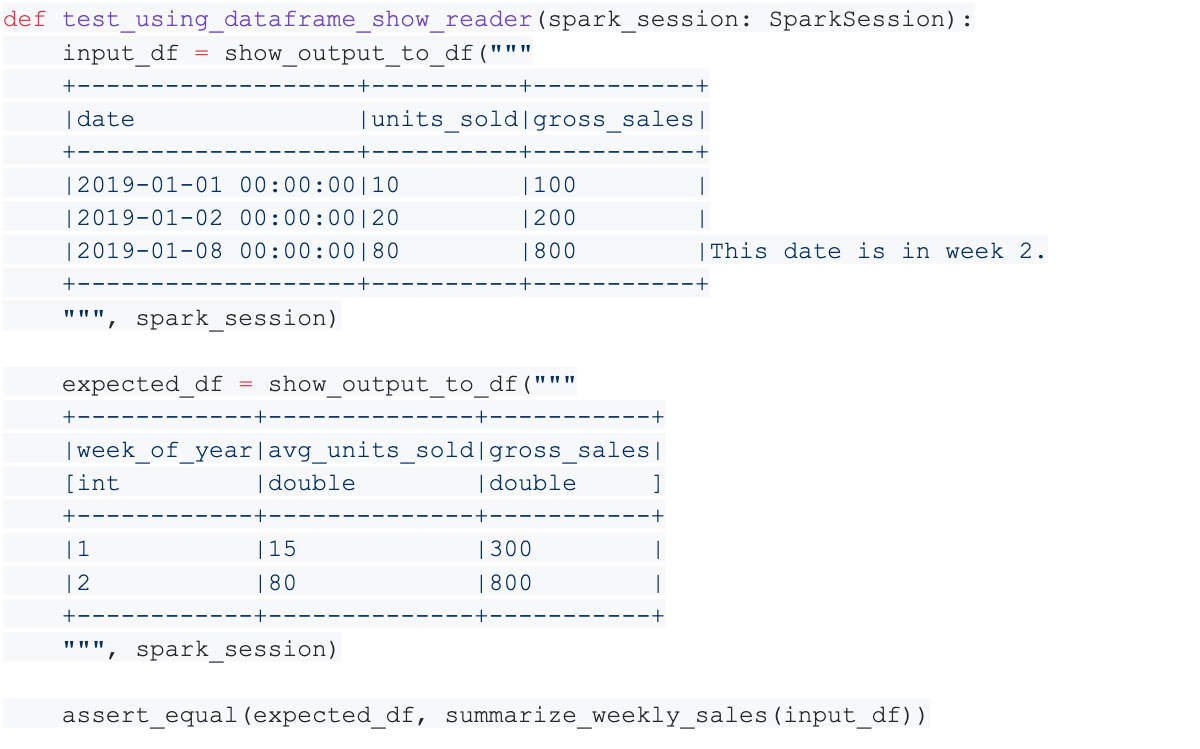
In the second test example, the show_output_to_df function accepts as input a string containing the output of a Spark DataFrame.show() call and “rehydrates” it into a new Spark DataFrame instance that can be used for testing.
In the first version, the setup portion of the test contains 18 lines, and it may take a few moments to digest the contents of the input rows. In the second version, the setup portion contains nine lines and displays the input data in a more concise tabular form that may be easier for other programmers (and our future selves) to digest when we need to maintain this code down the road.
If the method under test was more complicated and required more rows and/or columns in order to adequately test, the length of the first test format would grow much more quickly than that of the test using the DataFrame Show Reader.
As opposed to initializing some sort of collection of collections (such as a list of rows) or building a Spark SQL INSERT statement as a string, the show() output requires only a single pipe character between columns. This can reduce the width of the input data in the code file, making it easier to visually absorb more input without needing to scroll down or to the right.
However, show() output frequently is wide enough that it exceeds the recommended maximum line lengths for various language style guides and does, in fact, scroll out of view to the right of the screen.
The display of tabular data such as this is one of the few cases where we allow ourselves to exceed recommended maximum line lengths. The reasoning is that in the case of tabular data, exceeding the maximum line length when necessary actually makes the code more readable than the alternatives.
Notice also that the show_output_to_df function gives us a convenient way to create an expected_df to pass to the assert_equal function (to check DataFrame equality) that is included in the package. In addition to allowing this compact display of the expected numbers of rows and columns and data, assert_equal checks that the DataFrame schemas match, which the first version of the test does not do.
Installation
To install the package for use in your own package, run:
pip install py-dataframe-show-reader
Where to Find It
You can find py-dataframe-show-reader here: https://github.com/internetsystemsgroup/py-dataframe-show-reader/
We plan to release a Scala version in the future. If you have any suggestions that might make it even more useful, please participate in the project on GitHub.
Our engineering culture values and encourages experimentation and innovation with healthy doses of testing and verification of the outcomes. If you’d really like to get involved in some exciting and innovative development, we’re hiring! To join VideoAmp’s Engineering group, visit videoamp.com/careers.
