Profiles of Innovation: Arriving at Continuous Integration and Deployment: From ECS to Kubernetes Using Docker

Introduction
We decided early on at VideoAmp that software releases shouldn’t be a huge ceremony where deployment gods give their blessing before software makes it into production. Nor should they require a ton of effort in coordination and scheduling. Instead, we collectively decided to make the release process as painless as possible with a focus on maximizing velocity, productivity, and sustainability. Moreover, the mission of the infrastructure team is to enable engineers to create and build — not to restrict.
We’ve held on to this belief from the get-go, but the tools, release process, and methods we employ have evolved over time.
Pre-Docker
In our pre-Docker ecosystem, Chef was king. We ran Chef via OpsWorks in AWS to provision systems, manage releases, and restart services. We had Chef cookbooks for everything from installing programming languages, libraries, setting up configuration files, restarting services, upgrading packages, etc. Once the cookbooks were written and corresponding stacks and layers created, the keys were turned over to engineers. They were free to execute Chef recipes at will and manage releases.
As the company grew, we started to hit a few pain points. The first was environment configuration. For example, developers were on their own to configure local environments. This became more of a nuisance as the number of applications, hardware, and operating systems grew. Similarly, configuring production and staging environments for new projects required a knowledge transfer between at least one developer and one infrastructure person in order to translate the install and configuration steps into Chef cookbooks. This wasn’t ideal since it was a manual step that had to be scheduled between stakeholders. Secondly, configuration deviation started to become more of a problem as the number of hands touching the different environments increased. And because our environments were mutable, successful deployments between development, staging, and production environments was not guaranteed.
The Chef-only approach worked “fine” for a while, but as the number of services grew, as well as their complexity, it felt more and more like we were using a hammer to solve all of our problems when what we really needed was an array of tools.
Docker
Docker solved the first two pain points: repeatable environments and the “build once / run everywhere” problem. In this model, developers configure their own Dockerfiles which capture the commands necessary for an application to run. Once the container builds and runs initially, it should run everywhere (which proved true for the most part).
The benefits that immediately became apparent with Docker were the ability to run multiple containers on the same system and the ability to isolate resources and environments per container. Both later proved key to maximizing server resources.
However, the transition to Docker was not without challenges and this emanated once we had a few applications running in production. Our first iteration used Chef to install the Docker daemon on systems and to pull images locally. We used Supervisord to manage container state. This approach fell short of what we needed, so the search for a real container orchestration tool began.
The two docker orchestration tools we considered seriously were Amazon’s ECS service and Kubernetes. Since our entire infrastructure was in Amazon Web Services, and we didn’t have much in-house Kubernetes knowledge, we decided on ECS.
ECS
Amazon Elastic Container Service (ECS) is a docker orchestration tool. Like many of the other AWS services, we found ECS intuitive and easy to use. ECS has a concept of clusters, services, and tasks which are used to configure and deploy containers. The biggest selling point for us was the fact that we could use the ECS UI to manage releases, making it easy for us to hand over the keys to developers to manage their own releases. About a year later, our application stack spanned dozens of microservices, all Dockerized, and all managed by ECS. Outside of a few quirks, ECS worked great for us.
Kubernetes
In late 2017, we made a decision to move a large portion of our infrastructure away from the cloud and into a physical data center. Our reasons for doing so, have been written about in a previous post. The on-premise systems brought forth new challenges, and unfortunately, ECS was no longer an option.
We found ourselves again at a crossroads: 1) keep ECS and maintain two deployment methods, or 2) ditch ECS altogether and find a solution that accommodated our hybrid environment. We settled on the latter and this time around, it was the right choice. After a quick proof of concept, we selected Kubernetes as our container orchestration tool of choice, and started to put together a migration plan.
The migration process from ECS to Kubernetes was not difficult. We spent a couple days provisioning servers and standing up Kubernetes clusters. Once the clusters were up, we started migrating applications over, one at a time. The migration process involved translating ECS tasks definitions to Kubernetes deployment files and then using those files to deploy applications. The process was a joint effort between developers and infrastructure. Once the new services were up, tuning and verification was done before moving traffic over.
Kubernetes Deployments
Establishing a well-defined process for deployments moving forward was a challenge in its own right. Needless to say, we didn’t get it right the first time. We went through a series of iterations to get to an acceptable state. We took into account the engineers’ feedback after each one and continuously improved upon a system that met their needs. A brief description of each iteration follows.
Iteration One: Manifest Files and Kubectl
Our first deployment process was very much a manual process. Developers would build and push docker images to Docker Hub. Once the image becomes available, the corresponding manifest file is updated with the new image tag. The deployment is executed via the Kubernetes command-line tool, Kubectl, using the updated config file. In the same spirit as before, we handed the deployment keys over to the rest of the teams as we had done previously with OpsWorks and ECS.
We hit two major hurdles in this iteration. First, the added overhead of learning kubectl front-to-back was not ideal. Second, we started running into issues were folks were forgetting to commit configuration changes. This is a big problem because outdated configurations can cause subsequent releases to fail or applications to launch with stale configurations. Both of these factors led us back to the drawing board.
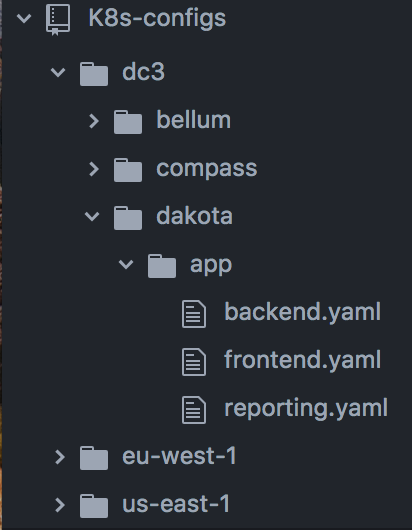
The one notable thing we did at this stage was grouping all manifest files into a single configurations repository. The repository is organized by region (Data Center location or AWS region), and then by Kubernetes cluster name. Each cluster has an “apps” folder where application deployment files live.
Iteration Two: Kubernetes Application Deployer
We needed a solution that removed the hard requirement on Kubectl as well as the need to manually commit changes to the configurations repository. After some discussion, we decided to build a rest API service that would handle both: k8s-app-deployer

k8s-app-deployer requires the following parameters: region, Kubernetes cluster name, deployment file name, docker image tag, and deployment method. The application uses the values of these to run deployments and commit the changes to the configuration repository.
A deployment in this iteration is kicked-off when a developer pushes an image up to Docker Hub. Docker Hub fires off a webhook to the k8s-app-deployer once the image is received. The deployer performs the deployment. Although we use Docker Hub as the trigger for a deployment, k8s-app-deployer can be called from anywhere including a developer’s local machine.
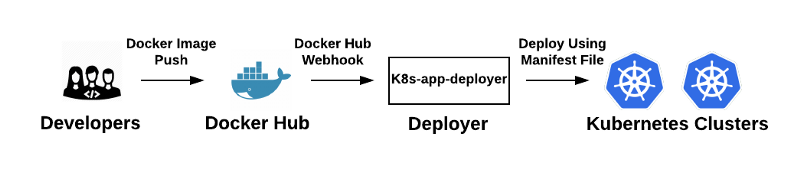
The obvious shortcoming of this approach is that any push to a Docker Hub repository fires off a deployment, which can lead to unintended deployments. To add to this, we were missing a CI system in the pipeline.
Iteration Three: The addition of CI
The previous iteration made it really easy to deploy applications but we were lacking a proper CI. We counted on developers to run tests locally before deploying; definitely not ideal. So we introduced a CI system in this iteration: SemaphoreCI.
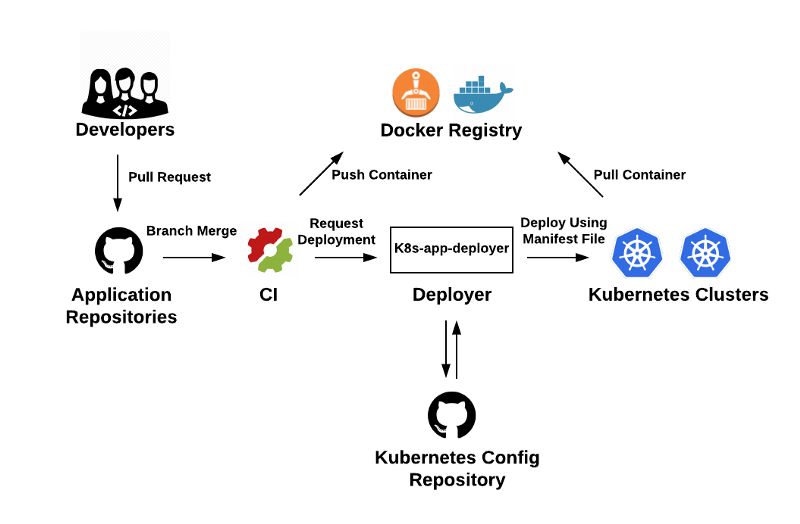
Here, a typical deployment starts off with a GitHub pull request. The code is reviewed and merged into one of three branches: dev, stage, master. The branches are mapped to the corresponding environments: development, staging, and production. A merge into one of the three branches triggers the CI. The CI, in turn, fires off an image build and runs the corresponding tests. If tests fail, the deployment process stops. If tests pass, the Docker image is pushed up to a docker registry, and k8s-app-deployer is called by the CI system via a REST call. The k8s-app-deployer application works the same way as it did in Iteration Two. It uses the parameters passed by the CI system to deploy the new image out to the correct Kubernetes cluster. Likewise, changes to the configuration files are checked into the configuration repository automatically. Finally, the deployer reports deployment event to Slack and a Kafka topic for observability.
One of the benefits of this architecture is that it is flexible and can easily be updated or extended. For example, any of the following components, GitHub, SemaphoreCI, Docker Hub can be swapped out with other solutions; say, BitBucket, CircleCI, or ECR. Similarly, we can easily add another CI without affecting the pipeline above. We’d simply have a second CI calling k8s-app-deployer.
Closing Words
The mission of the infrastructure team from the very beginning has been to empower others to efficiently create and iterate at scale. To this end, we’ve focused on making deployments as painless as possible. We started off with manual deployments triggered via Chef runs to now having fully automated deployments triggered by a repository branch merge. Through the process, the number of daily releases has increased significantly. We’ve gone from an average of a few releases per week, to more than 50 per day. The deployment process has evolved over time and will continue to do so in order to meet the needs of our team.
