Profiles of Innovation: What We Learned Migrating Off Cron to Airflow

The VideoAmp data engineering department was undergoing pivotal change last fall. The team at the time consisted of three data engineers and a system engineer who worked closely with us. We determined as a team how to prioritize our technical debt.
At the time, the data team was the sole owner of all the batch jobs that provided the feedback from our real-time bidding warehouse to the Postgres database that populated the UI. Should these jobs fail, the UI would be out of date and both our internal traders and external customers would be making decisions on stale data. As a result, meeting the SLAs of these jobs was critical to the success of the platform. Most of these jobs were built in Scala and utilized Spark. These batch jobs were orchestrated by Cron — a scheduling tool built into Linux.
Pros of Cron
We identified that Cron was causing a few major pain points that were greater than its benefits. Cron is built into Linux, so it requires no installation out of the box. In addition, Cron is fairly reliable which makes it an appealing option. As a result, Cron is a great option for proof of concept projects. However, scaling with Cron doesn’t work well.
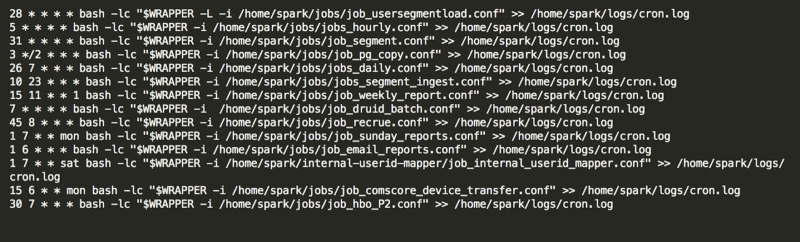
Cons of Cron
The first problem with Cron was that changes to the crontab file were not easily traceable. The crontab file contains the schedule of jobs to run on that machine. This file contained the scheduling of jobs across projects yet it was never tracked in source control or integrated into the deployment process of a single project. Instead, engineers would edit as needed, leaving no record of edits across time or project dependencies.
The second problem was that job performance was not transparent. Cron keeps a log of job outputs on the server where the jobs were run — not in a centralized place. How would a developer know if the job is successful or failed? Parsing a log for these details is costly both for developers to navigate and expose to downstream engineering teams.
Lastly, rerunning jobs that failed was ad hoc and difficult. By default Cron has only a few environment variables set. A novice developer is often surprised to find the bash command stored in the crontab file will not result in the same output as their terminal, because their bash profile settings have been stripped from the Cron environment. This requires the developer to build up all dependencies of the environment of the user that executes the command.
Clearly, many tools need to be built on top of Cron for it to be successful. While we had a few of these issues marginally solved, we knew that there were many open source options available with more robust feature sets. Collectively, our team had worked with orchestration tools such as Luigi, Oozie, and other custom solutions, but ultimately our experience left us wanting more. The promotion of AirBnB’s Airflow into the Apache Incubator meant it held a lot of promise.
Setup and Migration
In typical hacker fashion, we commandeered resources from the existing stack in secret to prove out our concept by setting up an Airflow metadb and host.
This metadb holds important information such as Directed Acyclic Graph (DAG) and task inventory, performance and success of jobs, and variables for signaling to other tasks. The Airflow metadb can be built on top of a relational database such as PostgreSQL or SQLite. By having this dependency, airflow can scale beyond a single instance. We appropriated a PostgreSQL RDS box that was used by another team for a development environment (their development sprint was over and they were no longer utilizing this instance).
The Airflow host was installed on our spark development box and was part of our spark cluster. This host was set-up with LocalExecutor and runs the scheduler and UI for airflow. By installing on an instance in our spark cluster, we gave our jobs access to the spark dependencies they needed to execute. This was key to successful migration that had prevented previous attempts.
Migration from Cron to Airflow came with its own challenges. Because Airflow was now owning the scheduling of tasks, we had to alter our apps to take inputs of a new format. Luckily, Airflow makes available the necessary meta information to the scheduling scripts via variables. We also stripped our applications of much of the tooling we had built into them, such as push alerting and signaling. Lastly, we ended up splitting up many of our applications into smaller tasks to follow the DAG paradigm.
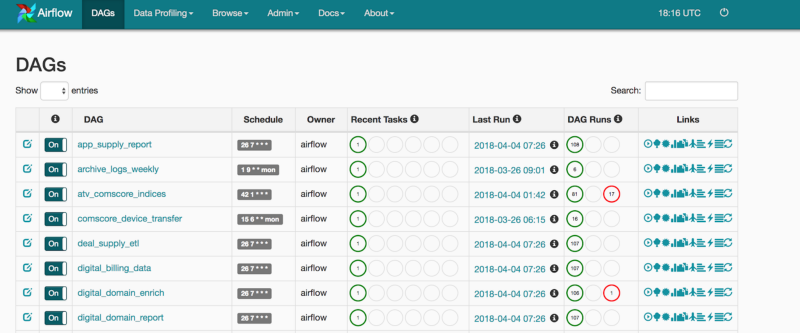
Lessons learned
- Applications were bloated By using Cron, scheduling logic had to be tightly coupled with the application. Each application had to do the entire work of a DAG. This additional logic masked the unit of work that was at the core of the application’s purpose. This made it both difficult to debug and to develop in parallel. Since migrating to Airflow, the idea of a task in a DAG has freed the team to develop robust scripts focused on that unit of work while minimizing our footprint.
- Performance of batch jobs improved prioritization By adopting the Airflow UI, the data team’s batch job performance was transparent to both the team and to other engineering departments relying on our data.
- Data Engineers with different skill sets can build a pipeline togetherOur data engineering team utilizes both Scala and Python for executing Spark jobs. Airflow provides a familiar layer for our team to contract between the Python and Scala applications — allowing us to support engineers of both skill sets.
- The path to scaling scheduling of our batch jobs is clear With Cron, our scheduling was limited to the one machine. Scaling the application would require us to build out a coordination layer. Airflow offers us that scaling out of the box. With Airflow, the path is clear from LocalExecutor to CeleryExecutor, from CeleryExecutor on a single machine to several Airflow workers.
- Rerunning jobs has become trivial With Cron, we would need to grab the Bash command that executed and hope that our user environment was similar enough to the Cron environment to recreate the error for us to debug. Today, with Airflow, it is straightforward for any data engineer to view the log, understand the error, and clear the failed task for a rerun.
- Alerting levels are appropriate Prior to Airflow, all alerts for batch jobs would be sent to the same email alias as alerts for our streaming applications. With Airflow, the team built a Slack operator that can uniformly be called for all DAGS to push notifications. This allowed us to separate the urgent failing notifications from our real-time bidding stack from the important — but not as immediate — notifications from our batch jobs.
- One poorly behaving DAG could bring down the whole machine Set guidelines for your data team to monitor the external dependencies of their jobs so as not to impact the SLAs of other jobs.
- Rotate your Airflow logs This should go without saying, but Airflow is going to store the logs of the applications it calls. Be sure to rotate logs appropriately to prevent bringing down the whole machine from lack of disk space.
Five months later, the data engineering team at VideoAmp has nearly tripled in size. We manage 36 DAGs and counting! Airflow has scaled to allow all of our engineers to contribute and support our batch flows. The simplicity of the tool has made the on boarding of new engineers relatively pain-free. The team is quickly developing improvements like uniform push alerting to our slack channel, upgrading to Python3 Airflow, moving to CeleryExecutor, and making use of the robust features Airflow provides.
